

Confluent 2024-1Q 決算の内容をまとめていきます。
決算資料
- Investor Presentation
- Earnings Report
- GenAI 実現における Confluent の役割
- Confluent が提供するもの
- ユースケースと顧客の採用
- GenAI の最新イノベーション
- GenAI パートナーシップ
- Confluent データ ストリーミング プラットフォーム
- 完全なデータ ストリーミング プラットフォームの主要な柱
- Confluent DSP イノベーション
- Confluent DSP の採用
- Tableflow
- 分析資産内のクローズド データ
- Apache Iceberg
- Tableflowの存在意義
- Flink GA
- GenAI の牽引力
- AI モデル推論
- トランスクリプトの要約
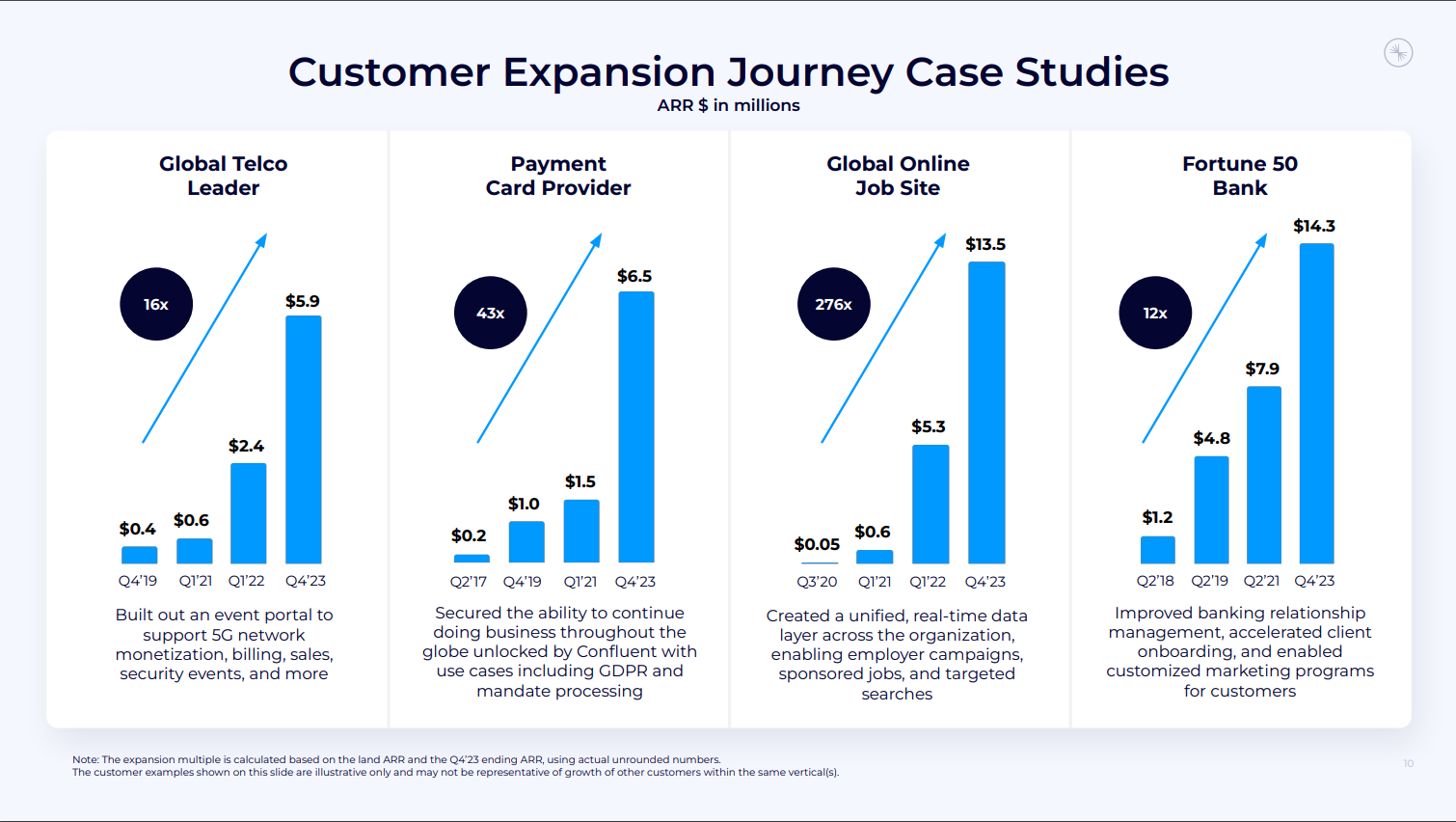
- 業績概要
- 消費転換の取り組み
- Kafka Summitの成功
- 新製品「Tableflow」の発表
- Flinkの進展
- 第1四半期の業績詳細
- 営業利益とキャッシュフロー
- マルチプロダクトの成長
- 質疑応答セッション
Investor Presentation

Earnings Report


GenAI 実現における Confluent の役割
GenAI は、多くの企業にとって引き続き最優先事項です。しかし、ほとんどの企業は、LLM だけでは十分ではないことに気づき始めています。RAG または検索拡張生成は、幻覚を回避し、きめ細かなアクセス制御を可能にする方法で、強力な LLM モデルをドメイン固有のデータ セットに拡張するための GenAI の共通パターンとして登場しました。
データ ストリーミング プラットフォームは、RAG 対応のワークロードをコンテキストと信頼性の高いデータで強化する上で重要な役割を果たします。これにより、企業はビジネスを支えるシステムからリアルタイム データの継続的なストリームを活用し、それを AI アプリケーション用のベクトル データベースで使用できる適切な形式に変換できます。
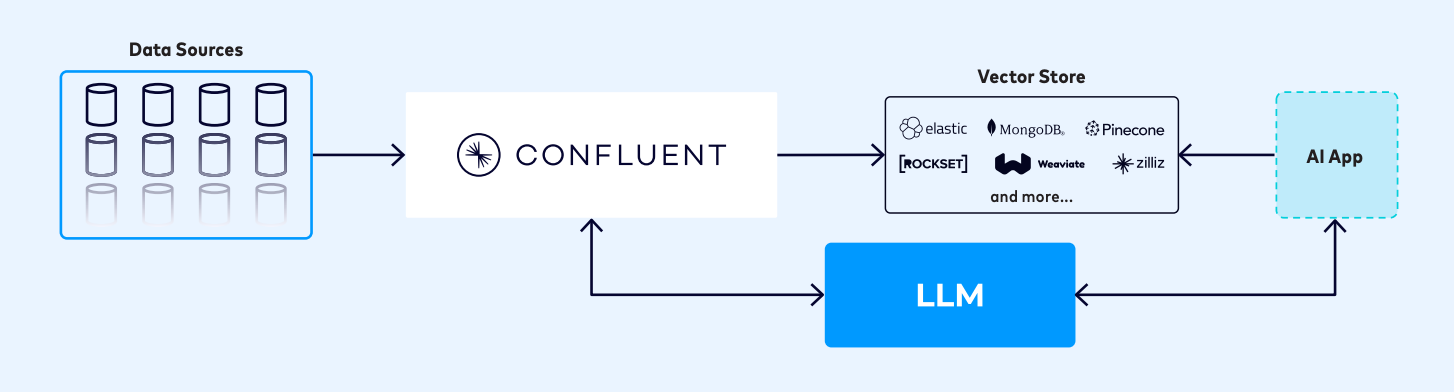
Confluent が提供するもの
Confluent の完全なデータ ストリーミング プラットフォーム (DSP) を使用すると、組織は、高度なモデルの構築と微調整のためのリアルタイムの真実の共有ソースを構築し、クエリ時にリアルタイムのコンテキストをもたらし、再利用可能でユニバーサルなデータ製品で新しい AI アプリとモデルが利用可能になったときにイノベーションの摩擦を軽減し、信頼できるリアルタイム データ ストリームで幻覚を最小限に抑えるために、管理され、セキュリティ保護された、信頼できる AI を構築できます。
ユースケースと顧客の採用
当社の顧客ベースで確認されている人気の GenAI ユースケースには、次のものがあります:
- カスタマー サービス チャットボット
- コパイロット / コンテンツ作成
- セマンティック検索
- 意思決定サポート
デジタル ネイティブ セグメントでは、大きな牽引力が見られます。OpenAI、Notion、Motive などの多くの GenAI 企業は、データ ストリーミングを使用して、接続された顧客エクスペリエンスを構築し、ビジネス オペレーションを効率化してよりリアルタイムにしています。また、幻覚のない、信頼できる、リアルタイムの GenAI ユースケースである GenAI アプリケーションを構築するための GenAI インキュベーターでも、驚くべき牽引力が見られます。
GenAI の最新イノベーション
Flink AI モデル推論により、データ処理と AI/ML タスクの両方に対応する統合プラットフォームを通じて、AI/ML アプリケーションの開発と展開を簡素化できます。AI モデル推論により、企業はデータ処理と AI ワークフロー間のシームレスな調整を可能にして運用の複雑さを軽減し、正確でリアルタイムの AI 主導の意思決定を実現できます。
GenAI パートナーシップ
顧客がビジネス全体から最新のコンテキスト データを使用して AI の可能性を最大限に引き出せるように、Confluent は AI およびベクター データベース分野の大手企業とのパートナーシップを拡大し続けています。
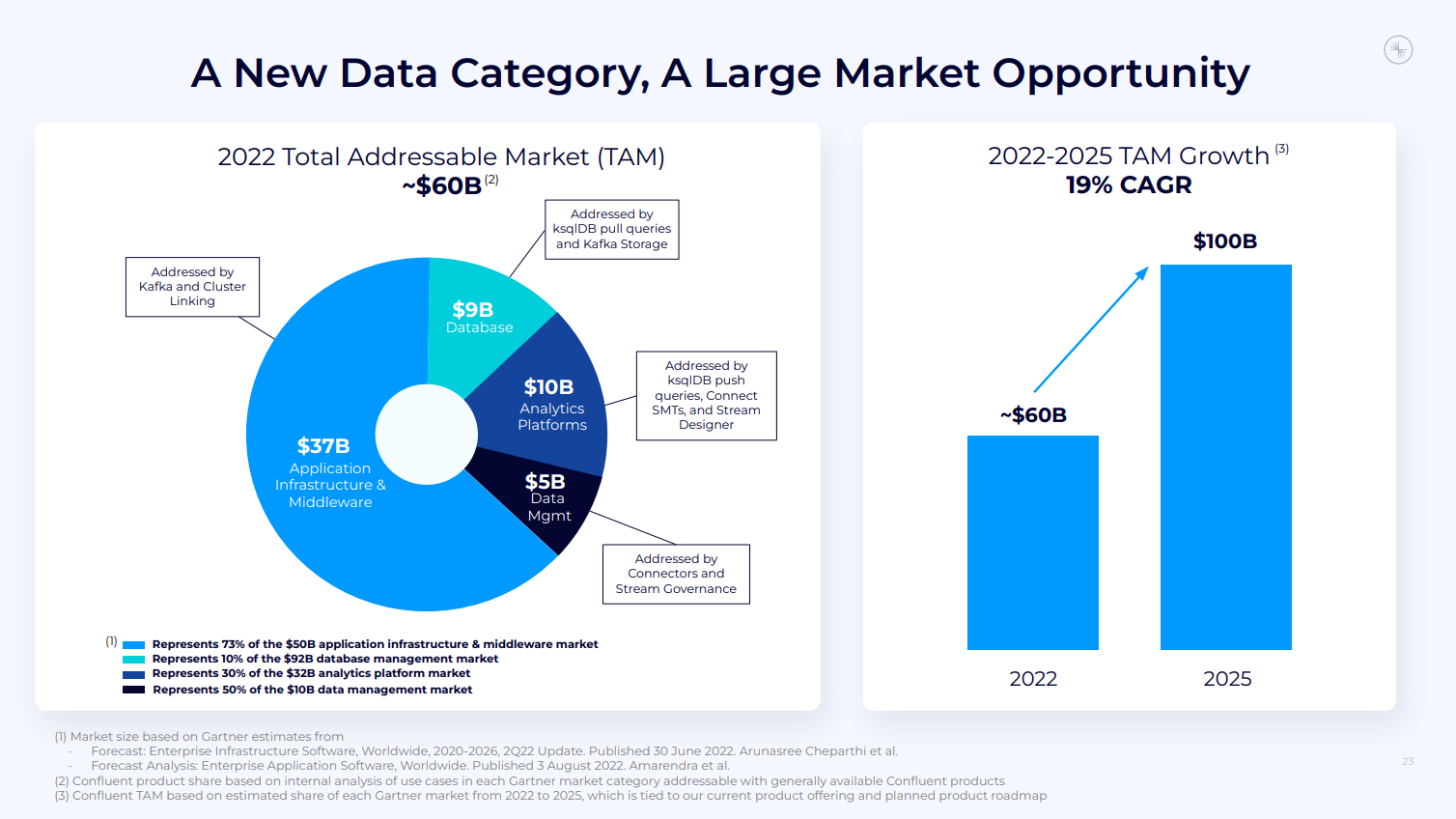
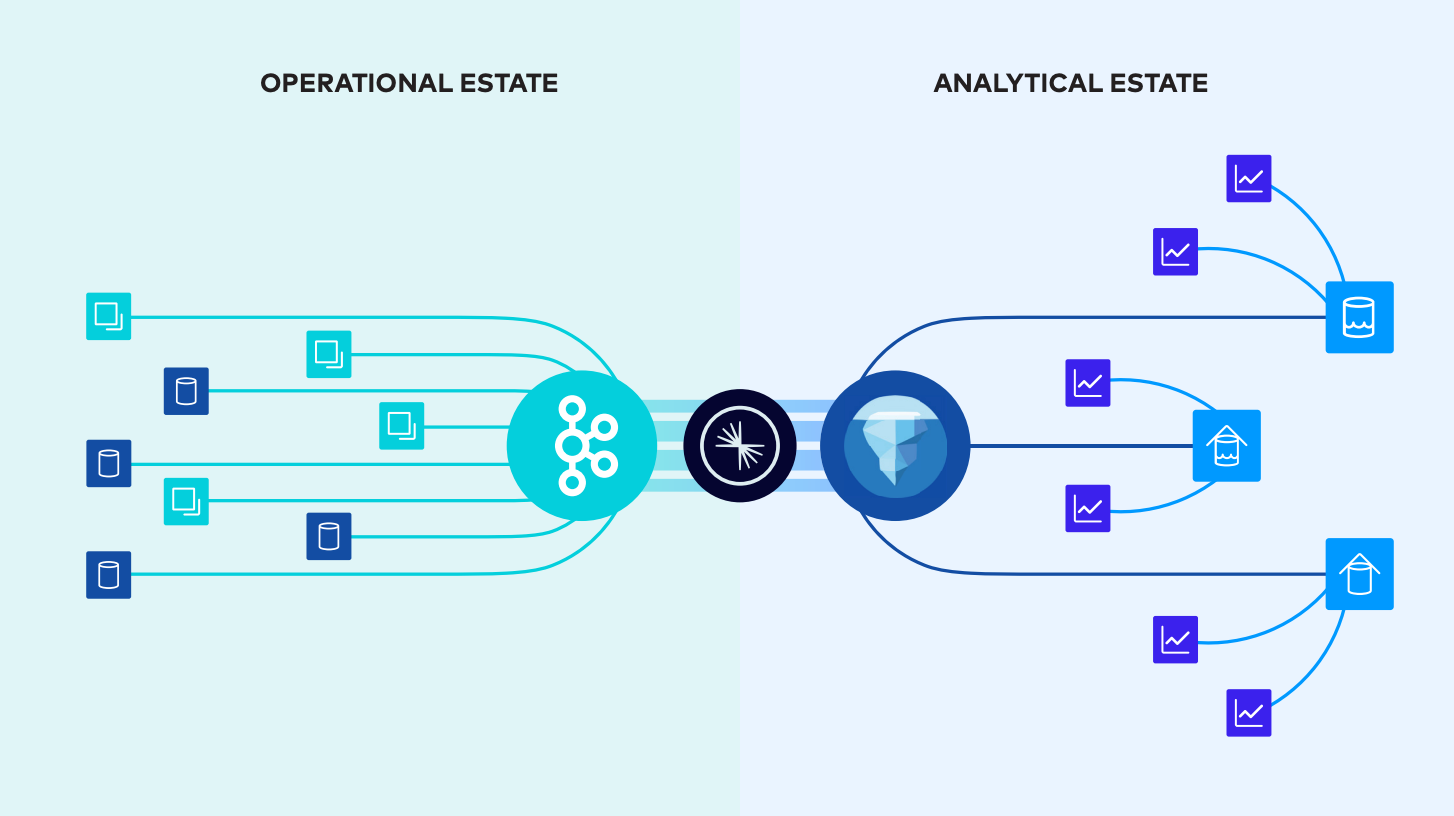
Confluent データ ストリーミング プラットフォーム
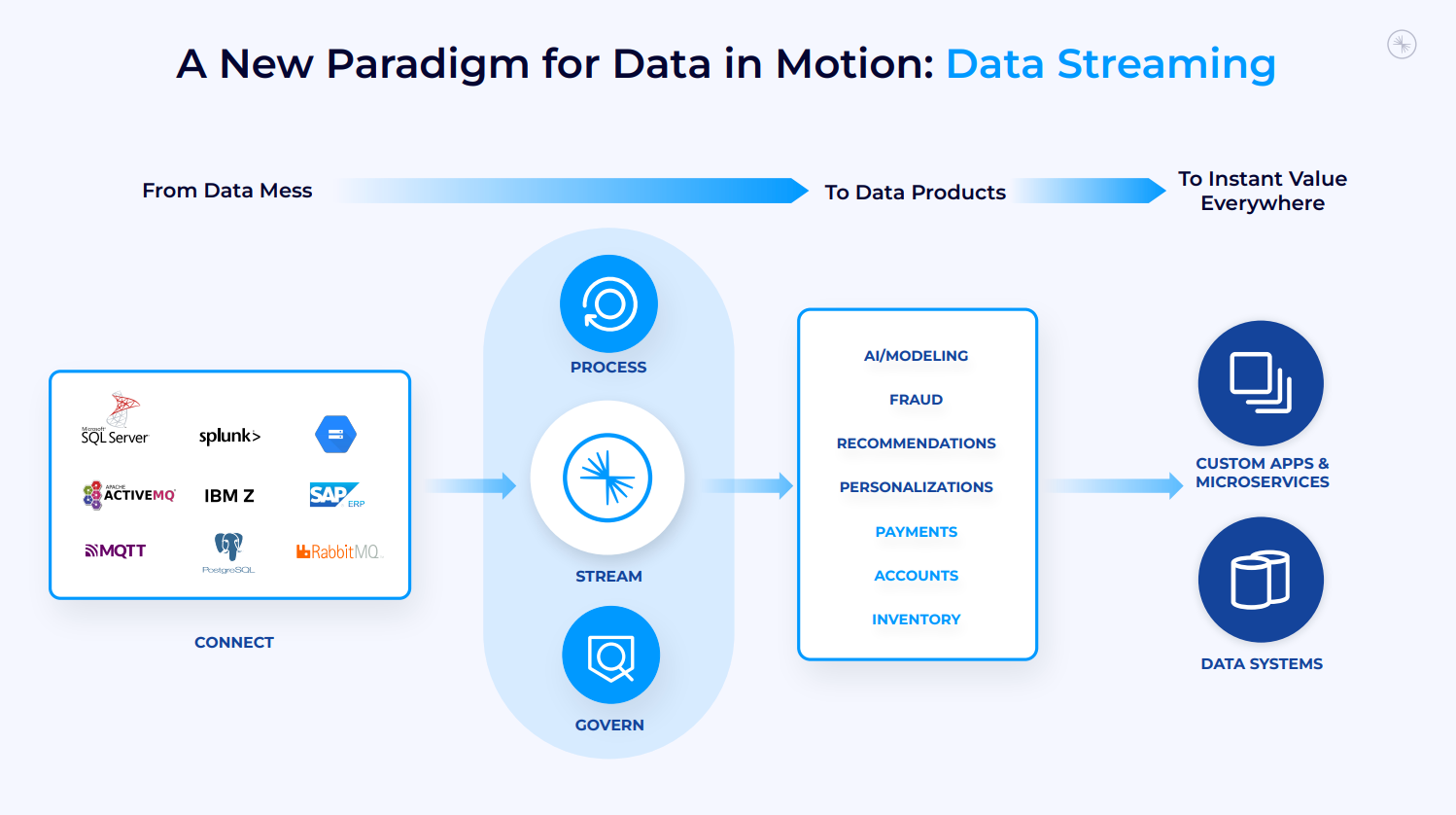
Confluent は、従来のデータ管理ツールによって作成された複雑で硬直したポイントツーポイント接続のスパゲッティのような混乱を、データを動かす好循環に変えるために、データ ストリーミング プラットフォーム (DSP) のカテゴリを開拓しました。
これにより、小売業者はリアルタイムの在庫システムを構築し、銀行はリアルタイムの不正検出を構築し、製造組織は組立ラインのリアルタイム診断を収集できます。Confluent を使用すると、組織はデータを動かし、デジタル ファーストの世界で勝利することができます。
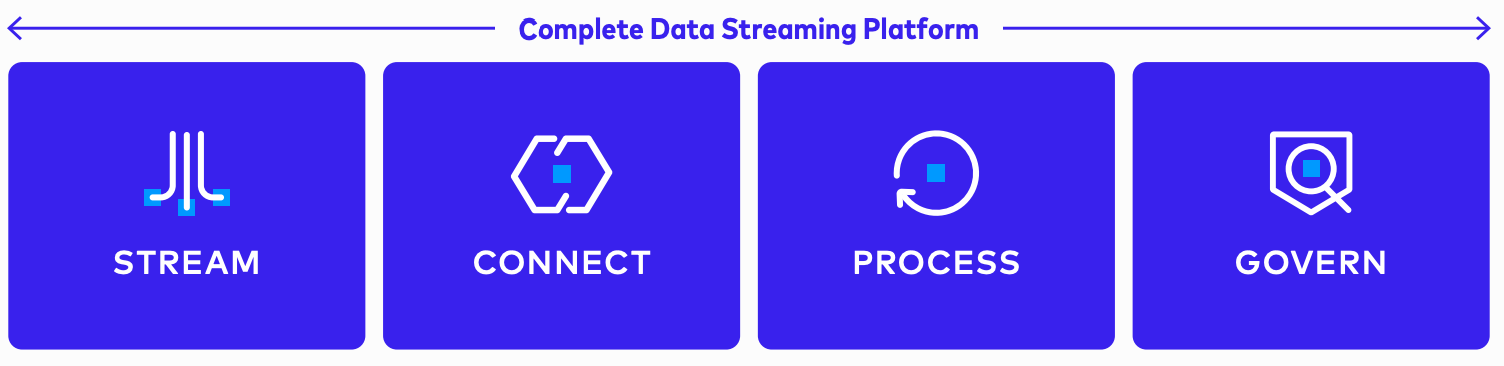
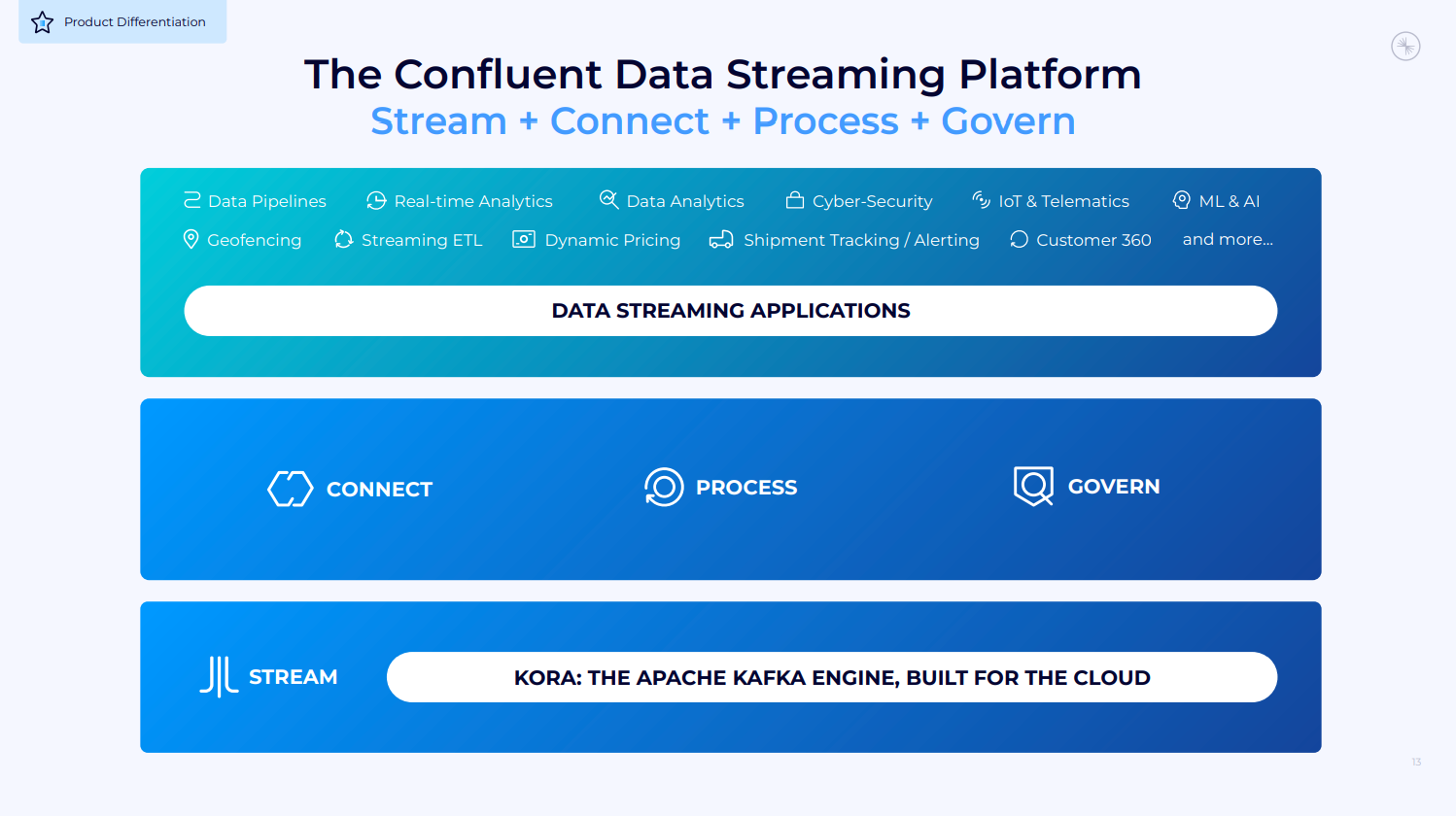
完全なデータ ストリーミング プラットフォームの主要な柱
当社の DSP は、データ処理のための完全な機能セットを実現し、ストリーミング データの好循環を実現します。
- ストリームから始まります。バッチ データは品質が低く、リアルタイムの世界のニーズを満たしません。
- 組織内のあらゆる場所からデータを接続し、継続的に移動する全体にシームレスに統合します。
- プロセス データ自体は便利ですが、ストリーム処理では、他のデータと組み合わせ、ビジネス コンテキストで強化すると、データの価値が無限に高まります。
- 最後に、ガバナンス。信頼性とセキュリティが確保されていないデータの価値は低くなります。
Confluent DSP イノベーション
DSP カテゴリにおける Confluent のリーダーシップは、Forrester や IDC などの大手アナリスト企業によって認められています。
当社は、2024 年の Kafka Summit Bangalore および Kafka Summit London で発表された 15 の主要な機能と価格の最適化 (Tableflow を含む)、および Confluent Cloud と Apache Flink 向け Confluent Platform の GA など、絶え間ない製品イノベーションのペースでリーダーシップの地位を拡大し続けています。
Confluent DSP の採用
当社のマルチ製品プラットフォームのこの価値提案は、お客様の共感を得ています。これにより、当社の成長ベクトルが強化され、さまざまな理由から、永続的かつ効率的な成長を推進するための滑走路が広がります。
- 接続、プロセス、ガバナンス: 各 DSP 製品には、Kafka よりも大きな独立したビジネスになる可能性があります。
- 接続、プロセス、ガバナンスはクラウドよりも大幅に速く成長しましたが、クラウド収益の約 10% を占めるに過ぎませんでした。
- マルチ製品の 10 万ドル以上の顧客は前年比 47% 増加し、強力なネットワーク効果により NRR が大幅に増加しました。
Tableflow
Tableflow は、Apache Iceberg と呼ばれるオープン テーブル形式を使用して、Confluent Cloud を通過するすべてのデータ ストリームをクラウド オブジェクト ストレージ内の構造化テーブルとして利用できるようにします。これが何を意味するのか、そしてなぜそれが非常に強力なのかについて、少し背景を説明しましょう。
分析資産内のクローズド データ
歴史的に、分析とデータ ウェアハウスの世界のデータは、ウォールド ガーデン内にデータを閉じ込めるクローズド システムに存在していました。分析の世界が複雑化するにつれて、データ ウェアハウス、データレイク、AI 製品、レポート システムが混在するようになりました。これにより、テクノロジ ベンダーには大きな価値がもたらされましたが、エンド ユーザーにとっては別のデータ サイロが作成されました。ただし、過去 5 年間で、クラウド オブジェクト ストレージ上でオープン データ形式とメタデータを標準化する傾向が生まれました。
Apache Iceberg
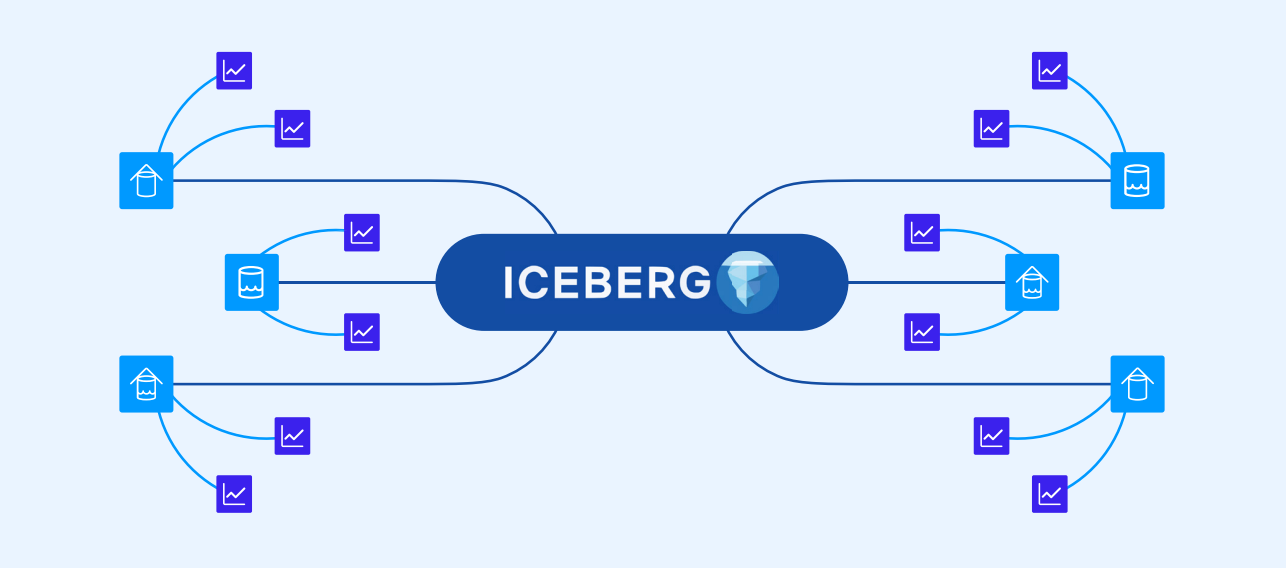
S3 などの安価なクラウド オブジェクト ストレージの台頭により、別の道が可能になりました。さまざまな分析システム間でデータを断片化する代わりに、データ テーブルをシステム間で共有できます。
Apache Iceberg は、クラウド オブジェクト ストレージ上のこれらのオープン分析テーブルの事実上の標準として登場しました。
Iceberg は、Apache Spark や Flink などのオープン ソース システムだけでなく、AWS Athena、Redshift、Google の BigQuery、Snowflake などの製品を含むデータ ウェアハウスおよびデータ レイクハウスの世界でほぼ普遍的にサポートされているオープン ソース プロジェクトです。
Tableflowの存在意義
Tableflow は単なるコネクタではありません。すでに Kafka と Confluent は、これらの分析システムへの最も一般的なデータ フィードの 1 つですが、Tableflow を使用すると、その統合をさらに深めることができます。クラウド ネイティブの Kafka 実装である Kora は、すでに Confluent Cloud にデータ ストリームを保存するためにクラウド オブジェクト ストレージに大きく依存していました。Tableflow を使用すると、ボタンをクリックするだけで、同じストリームを Iceberg テーブルとして直接開くことができます。つまり、データは一度定義され、一度保存され、複雑なマッピングや変換は必要ありません。
Tableflow は現在早期アクセス版で、最初のユーザーを獲得しています。
一部のベンダーにとって、Iceberg のようなオープン データ形式の台頭は脅威とみなされています。サイロに閉じ込められていたデータが処理および分析レイヤーのエコシステムに開放され、ベンダーがコスト、パフォーマンス、機能に基づいて公平な競争の場で競争できるようになり、新規参入者が大きなデータ グラビティを克服する必要がなくなるためです。
しかし、Confluent は、目標、そして実際ビジネス モデルがデータの共有を中心に構築されているため、このトレンドから恩恵を受ける独自の立場にあると考えています。そのため、Iceberg の台頭により、プラットフォーム内のストリームの価値を高めることができる非常に重要なデータの宛先が作成されます。これにより、Tableflow は、組織内のすべてのデータを開放して接続するという Confluent のビジョンの中心になります。この発表に対して、お客様から圧倒的に肯定的なフィードバックをいただいており、今後これをビジネスの重要な部分にしていきたいと考えています。
Flink GA
前四半期に、ストリーム処理の世界と、当社の Flink 製品がこの市場で勝利を収める独自の立場にある理由について説明しました。そして、当社の Flink 製品に対する関心と期待は驚くほど高まっています。プレビュー以来、約 600 の見込み顧客と顧客が Flink を試用しています。Kafka Summit London では、Apache Flink 向け Confluent Cloud の一般提供を発表しました。初期の顧客からのフィードバックは好調です。これらの顧客の多くが、時間の経過とともに大幅な消費を促進する本番アプリケーションに向けて準備を進めていることがわかります。
Kafka Summit Bangalore では、もう 1 つのエキサイティングな Flink 開発を発表しました。オンプレミス ソフトウェア製品である Confluent Platform に Flink を追加します。これにより、オンプレミスおよびハイブリッドの顧客は、データセンターで実行される重要なワークロードに Flink を採用できるようになります。
これらは Confluent にとって非常にエキサイティングなステップであり、唯一の完全なデータ ストリーミング プラットフォームとしての当社の地位を固めるものです。 Tableflow と Flink は Kafka を超える新しい機能であり、現代の企業で最も重要なデータ プラットフォームとなるであろうものの構築に向けた大きな進歩を表しています。
GenAI の牽引力
GenAI は多くの企業にとって引き続き最優先事項です。しかし、ほとんどの企業は LLM が単独で機能するものではないことに気づき始めています。
RAG または検索拡張生成は、幻覚を回避し、きめ細かなアクセス制御を可能にする方法で、強力な LLM モデルをドメイン固有のデータ セットに拡張するための GenAI の共通パターンとして登場しました。データ ストリーミング プラットフォームは、RAG 対応のワークロードをコンテキストと信頼性の高いデータで強化する上で重要な役割を果たします。これにより、企業はビジネスを支えるシステムからリアルタイム データの継続的なストリームを利用し、それを AI アプリケーション用のベクトル データベースで使用するのに適した形式に変換できます。
AI モデル推論
バンガロールの Kafka Summit で発表されたもう 1 つの発表は、この種の RAG アーキテクチャを容易にするものです。
Flink SQL での AI モデルとリモート推論のサポートです。この機能は、ソフトウェア開発者が推論と埋め込み計算をデータ処理に直接統合できるようにすることで、AI アプリケーションの開発と展開を簡素化するように設計されており、リアルタイム アプリに AI を導入することがこれまで以上に容易になります。
デジタル ネイティブ セグメントでは、OpenAI、Notion、Motive などの企業が GenAI を活用してほぼすべての業界で顧客体験を再構築しており、GenAI が特に大きな注目を集めています。
そのような顧客の 1 つは、コンタクト センターと顧客エンゲージメントを管理する AI 搭載の顧客インテリジェンス プラットフォームです。強力なコミュニケーション AI はプラットフォームの中心であり、コール センター マネージャー向けのリアルタイムの洞察の表示や、問題のある状況に対処するためにエージェントがすぐに支援や介入を必要とするタイミングの特定など、さまざまなユース ケースで使用されています。既存のアーキテクチャではリアルタイムの要求に対応できず、遅延が 1 分を超えることもありました。この遅延は、最新かつ継続的に更新されるデータへのアクセスを必要とする AI アプリケーションでは許容されませんでした。そこで、この顧客は高速でスケーラブルなデータ ストリーミングを実現するために Confluent Cloud を採用しました。Confluent をアーキテクチャの他のコンポーネントと統合することで、顧客は応答時間の遅延を 1 分以上から 10 ミリ秒まで大幅に短縮することができました。より高速で最新のデータとより多くのリアルタイムの洞察を利用できるようになったことで、顧客は顧客のニーズに適切に対応し、コンタクト センターと顧客エンゲージメントを管理するための貴重なツールと分析を提供できるようになりました。

しかし、GenAI を実践しているのはデジタル ネイティブだけではありません。もう 1 つの優れた例は、サプライ チェーンおよび調達ソリューションのグローバル リーダーである GEP Worldwide です。この 10 億ドルの収益を誇る企業は、世界最大の多国籍企業にソフトウェア、コンサルティング、マネージド サービスを提供しています。同社のソフトウェア製品には、チャットボットや意思決定支援ツールをサポートするために GenAI が組み込まれています。以前は、チームはオープン ソースの Kafka ショップでしたが、オープン ソースの運用と保守が負担になりすぎて、最終的には迅速な反復と革新の能力が阻害されました。そこで、Confluent に目を向けました。Confluent がソフトウェアの中枢神経系として機能することで、同社はカスタム アプリや運用および分析資産を含む数百のアプリケーション間でデータをより迅速に接続し、コンテキストに関連したリアルタイムの洞察を AI プラットフォームに提供できるようになりました。 Confluent は、製品とパートナー エコシステム全体で革新を続け、お客様が簡単に、信頼できるデータ ストリームを使用して AI 対応アプリケーションを迅速に拡張および構築できるようにします。
トランスクリプトの要約
業績概要
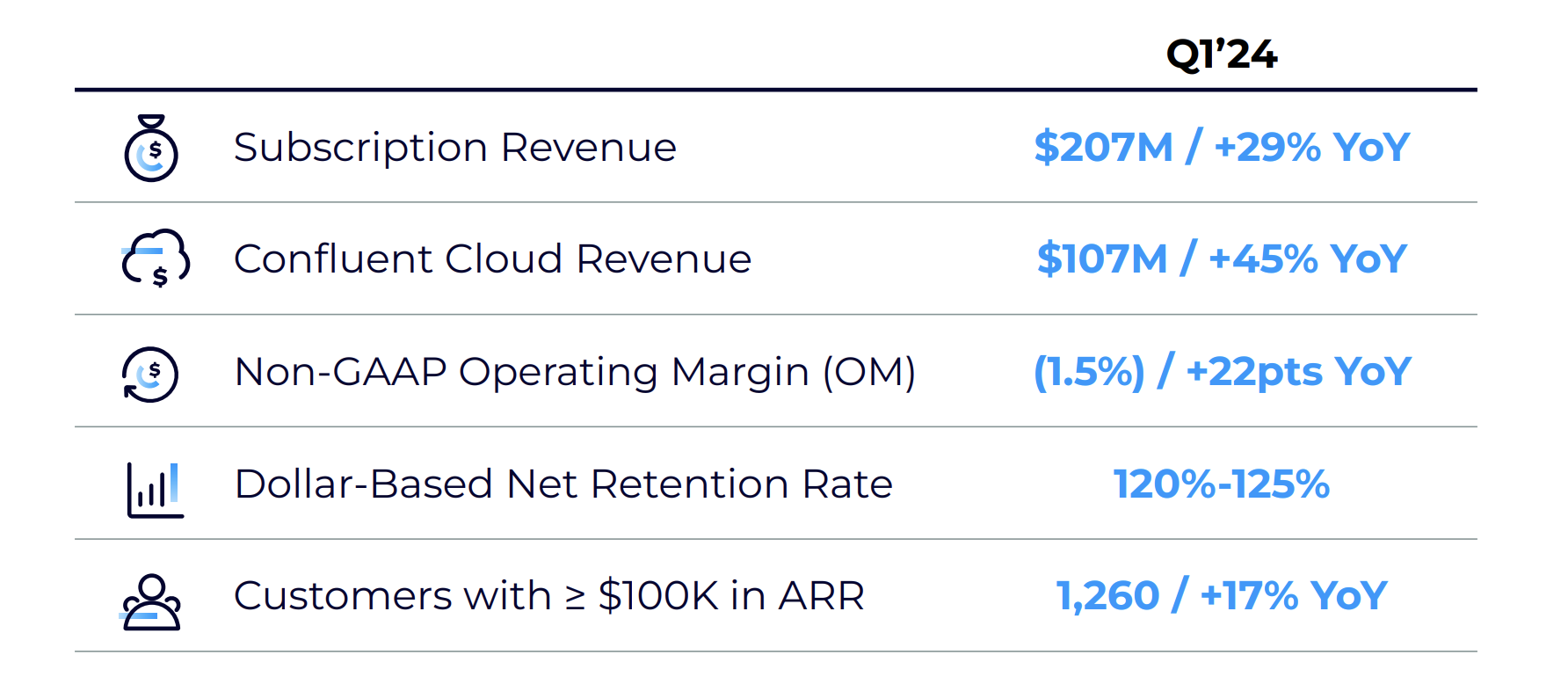
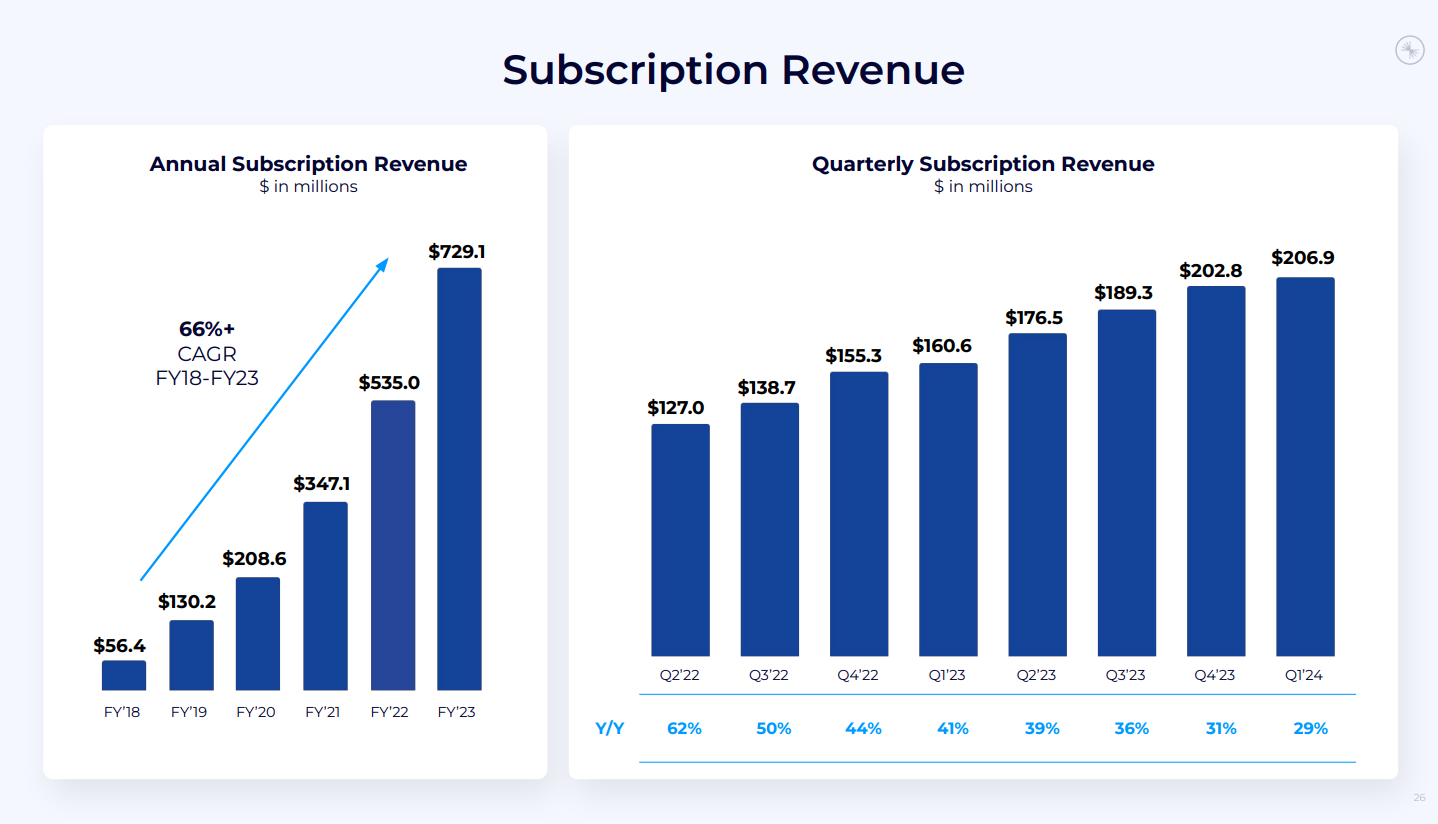
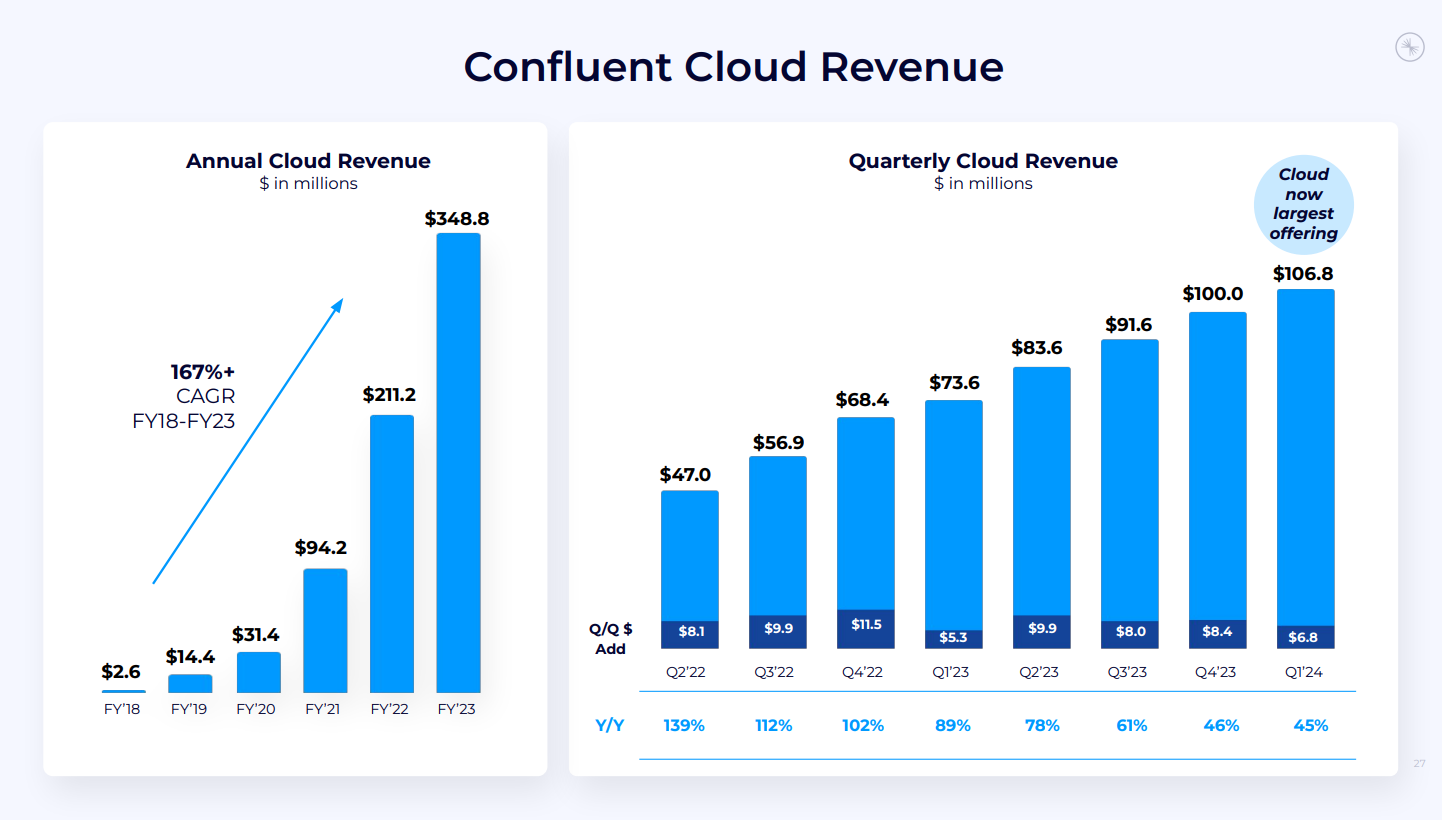
- 総収益: 2億1700万ドル(前年同期比25%増)。
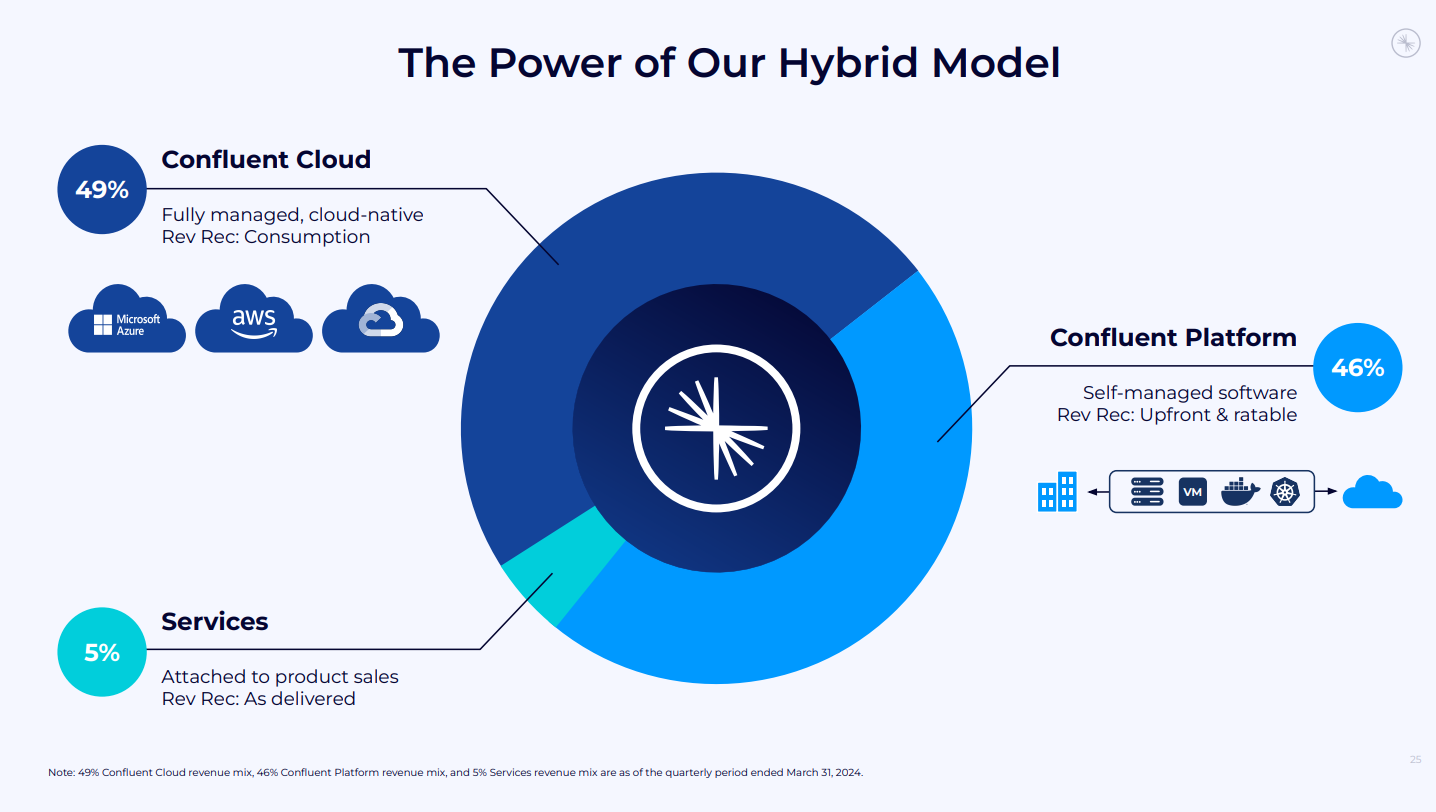
- Confluent Cloud収益: 45%増で1億700万ドルに到達(サブスクリプション収益の大部分を占める)。
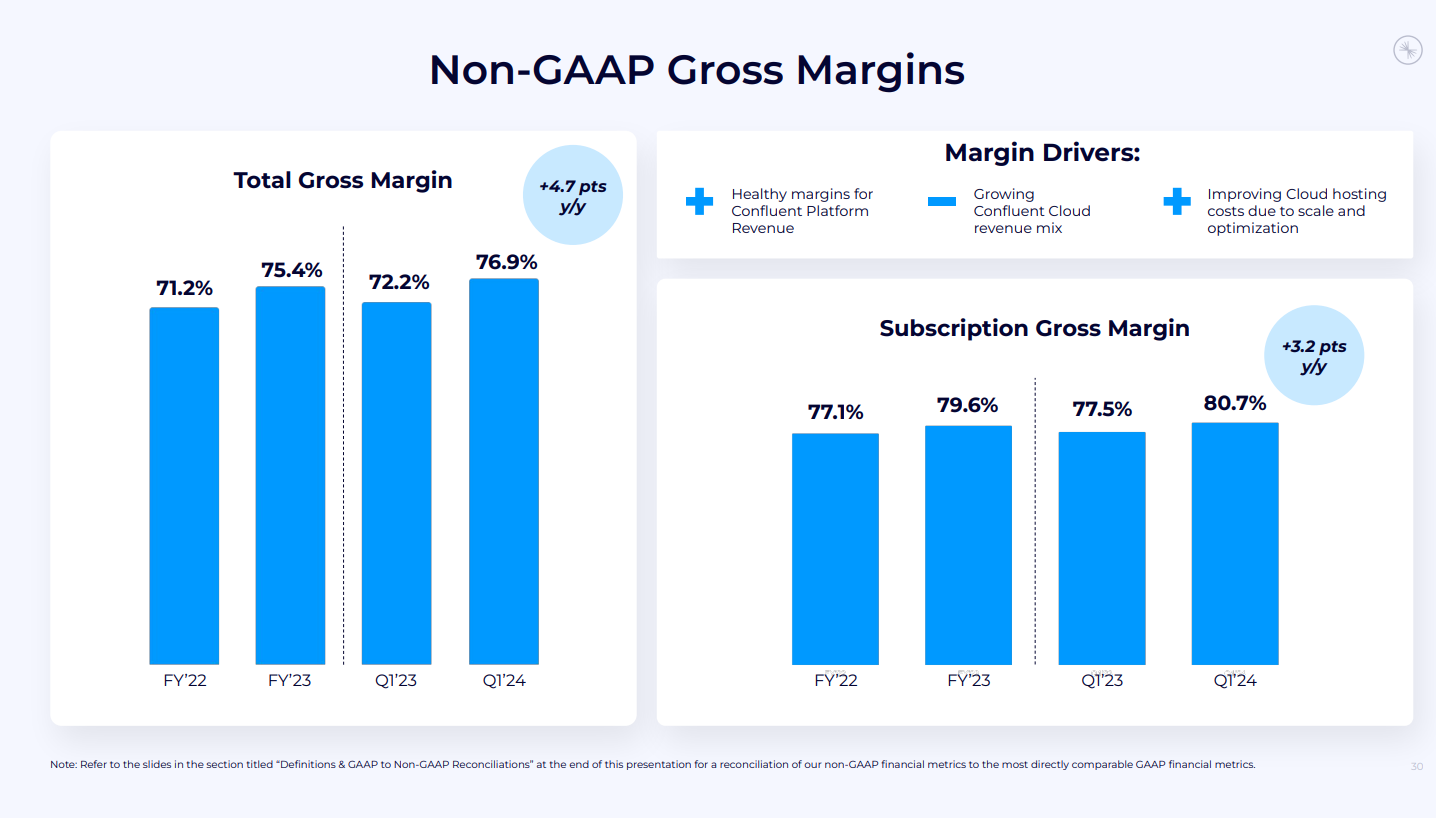
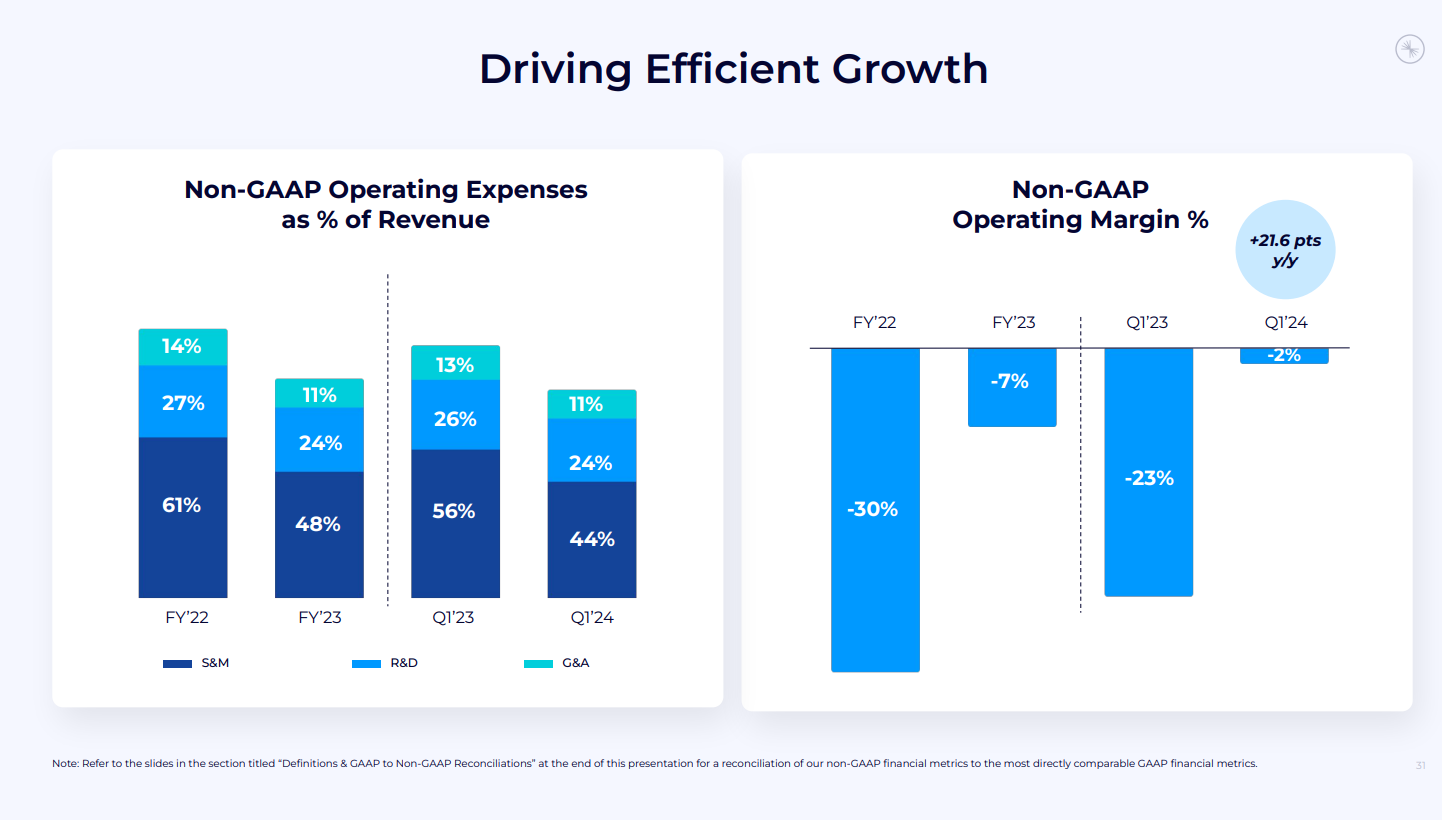
- 営業利益率: 22ポイント改善(非GAAPベース)。
- マクロ環境: 不安定ながらも安定化の兆しあり。
消費転換の取り組み
- 新戦略: クラウド向け営業報酬を消費量の増加と新規顧客獲得に注力する形に変更。
- 成果: 160件の新規顧客獲得(過去5四半期で最大)。高成長可能性のある顧客を的確にターゲット。
Kafka Summitの成功
- 開催地: ロンドンとバンガロール(APAC地域初)。
- 参加者: 現地およびオンラインで計7,000人以上。参加企業にApple、Bloomberg、Stripeなど。
- 発表: 15の新機能やパフォーマンス最適化。
新製品「Tableflow」の発表
- 機能: データストリームを構造化テーブルとしてクラウドオブジェクトストレージに格納。Apache Iceberg形式を採用。
- 目的: 分断されたデータを統合し、分析システム全体で共有可能に。
- 意義: Confluentの「データ共有」モデルに完全に一致。
Flinkの進展
- 採用状況: 約600の顧客がプレビューを試用。
- 新展開: クラウド版Flinkの一般提供を開始し、初期フィードバックは良好。
- オンプレミス: Confluent PlatformにFlinkを統合。
第1四半期の業績詳細
- サブスクリプション収益: 2億690万ドル(前年同期比29%増)。
- 地域別収益:
- 米国:1億2740万ドル(23%増)。
- 米国外:8980万ドル(28%増)。
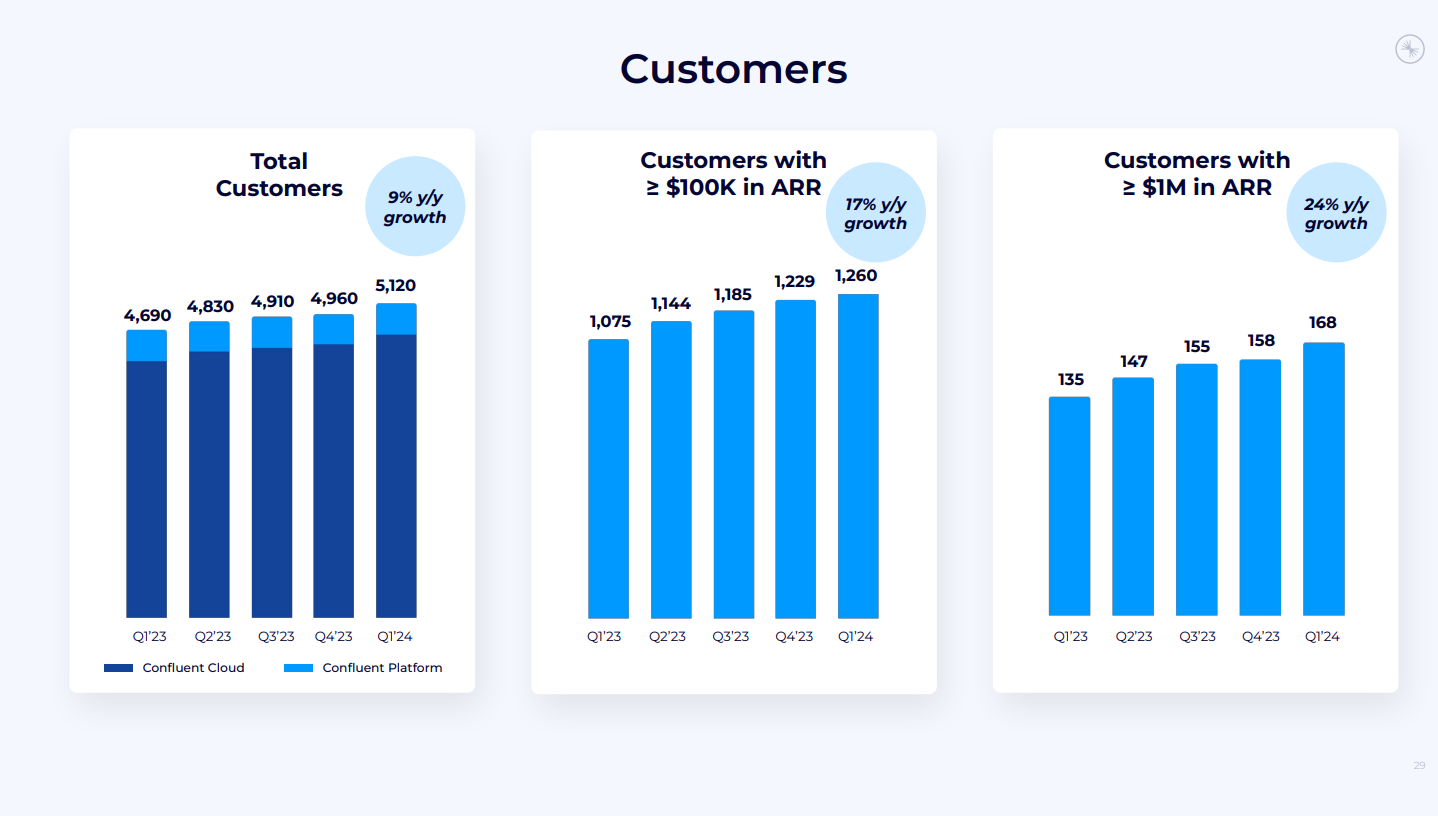
- 顧客基盤:
- 顧客数:5120社(160社増加)。
- ARRが10万ドル以上の顧客:1260社(17%増)。
- ARRが100万ドル以上の顧客:168社(24%増)。
営業利益とキャッシュフロー
- 営業利益率: 非GAAPベースでマイナス1.5%(22ポイント改善)。
- フリーキャッシュフロー: マイナス14.6%(33ポイント改善)。
- 現金・市場性証券: 19億1000万ドル。
マルチプロダクトの成長
- 主要製品: Connect、Process(Flink)、Govern。
- 収益貢献: クラウド収益の約10%を占める。最も成長率が高いセグメント。
- 戦略: 複数製品の採用を通じて、成長の加速と長期的な市場拡大を目指す。
質疑応答セッション
質問者1: Sanjit Singh(Morgan Stanley)
質問: マクロ環境について、昨年は新しいソフトウェア開発プロジェクトがかなり減速していたと記憶していますが、現在の状況はどうですか?また、販売体制の変革との関連性についても教えてください。
回答(ジェイ・クレップス):
全体的に安定化が見られます。昨年の多くの顧客はコスト最適化に重点を置いていましたが、新しい開発プロジェクトも少しずつ増えています。特にデジタルネイティブ企業では、昨年最も大きな打撃を受けた分、AI関連のイニシアチブが顕著に回復しています。また、消費転換についても、短期間で多くの変更を成功裏に進め、リスクを大幅に軽減しました。新規顧客の獲得が増加し、顧客層の質も向上しています。
質問者2: Matt Hedberg(RBC)
質問: DSP(データストリーミングプラットフォーム)の柱となる各製品の収益化戦略と、Tableflowの将来の収益化について教えてください。
回答(ジェイ・クレップス):
各製品には異なる収益化の仕組みがあります。例えば、コネクタはインスタンス数やデータ量に基づいて課金され、Flinkは処理時間に基づくモデルです。Governanceは基本料金に加え、利用規模に応じた料金体系となっています。Tableflowについては現在、初期アクセス段階のため具体的な価格はまだ決定していませんが、将来的に収益化の可能性があります。
質問者3: Raimo Lenschow(Barclays)
質問: Flinkの初期顧客の採用状況と市場の反応はどうですか?また、今後の成長市場としての見通しは?
回答(ジェイ・クレップス):
市場の反応は非常に好調です。デジタルネイティブ企業から大企業まで、幅広い顧客層がFlinkに大きな関心を寄せています。Flinkの一般提供(GA)開始により、今後は本格的な商用利用が進むと期待しています。
質問者4: Jason Ader(William Blair)
質問: Gen AI関連のプロジェクトにおいて、Confluentの技術がどのように使われていますか?また、それが収益にどのように影響を与えていますか?
回答(ジェイ・クレップス):
現在、Gen AI関連のプロジェクトは立ち上げ段階ですが、デジタルネイティブ企業がその推進力となっています。Confluentのプラットフォーム全体(コネクタ、Kora、Flinkなど)が、Gen AIのデータ供給チェーンを支えています。
質問者5: Michael Turrin(Wells Fargo)
質問: Flinkの採用において、どのような顧客が最適だと考えていますか?また、新製品がGA(一般提供)に移行したことで、販売プロセスへの影響はありますか?
回答(ジェイ・クレップス):
Flinkには幅広い関心があります。クラウド版では新規ユースケースに適しており、オンプレミス版では既存のFlinkワークロードを引き継ぐことが可能です。初期段階では、新しいユースケースが主流ですが、時間が経つにつれ既存のワークロードもクラウド版へ移行する傾向があります。製品のGA開始により、より多くの顧客が利用を開始し、収益への寄与も期待できます。
質問者6: Gregg Moskowitz(Mizuho)
質問: Apache Icebergが注目されていますが、Tableflowの正式提供後、既存顧客への採用曲線についてどのように予測していますか?また、新規顧客の獲得にも影響がありますか?
回答(ジェイ・クレップス):
Icebergに対する関心は非常に高く、既存顧客の採用や新規顧客の獲得に役立つと考えています。Tableflowは、顧客にデータを簡単に共有・管理できる仕組みを提供するため、Confluentのビジョンと強く一致します。ただし、現在はまだ初期段階のため、正確な採用速度や収益への影響は未知数です。
質問者7: Mike Cikos(Needham)
質問: 消費重視のモデル転換が、マルチプロダクトの採用を加速させていますか?それともまだ数字に表れるのは早いですか?
回答(ジェイ・クレップス):
はい、消費重視モデルはマルチプロダクトの採用を促進しています。以前は、営業チームは契約額(コミットメント)を中心に販売していましたが、現在は消費量に基づく報酬が即座に得られるため、追加製品の採用を積極的に推進しています。これにより、マルチプロダクト戦略が強化されています。
質問者8: Derrick Wood(TD Cowen)
質問: 最近の価格変更について教えてください。それが市場でどのような影響を与えると期待していますか?
回答(ジェイ・クレップス):
価格の調整は、複数の新製品や機能に対応するために行いました。これには、Kafka Summitで発表した新しいエンタープライズクラスタータイプや、スループット指向の価格設定変更が含まれます。これらの変更は、新規顧客獲得や消費拡大をスムーズにすることを目的としています。
質問者9: James Wood(Truist Securities)
質問: ガバナンス(Governance)の需要増加は、AIの準備としてのデータ管理の必要性に関連していますか?また、ガバナンス製品の収益化の可能性について教えてください。
回答(ジェイ・クレップス):
AIの登場により、データガバナンスの需要がさらに高まっています。これには、GDPRのような規制対応、データ安全性の確保、データ共有の効率化が含まれます。ガバナンス製品の収益化は、基本料金と利用量に応じた追加料金の組み合わせに基づいており、将来的にはさらに収益化が進むと考えています。